Week 9 (July 11 - July 15, 2022)
This week, I presented my project to Professor Ordóñez-Román, Veronica, and Ziyan. I put together an abstract based on my presentation to submit to this year’s Grace Hopper Celebration.
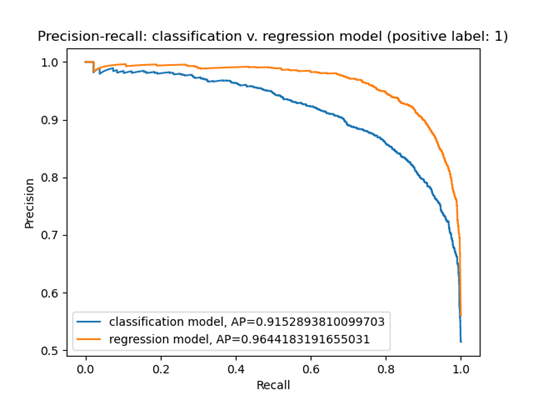
I also trained a regression model to predict normalized and raw numbers of distinct regions on my COCO complexity dataset. The advantage of training a regression model, as opposed to the classification models I had trained earlier, is that a regression model can take full advantage of the hundreds of thousands of captions in the dataset. For the classification model, since we used only the top and bottom 10% of captions corresponding to images with the most/fewest distinct regions, and predicted a simple binary label of “complex” or “noncomplex”, we missed out on all the images in the middle 80%! We can even use the regression model as a classification model by taking its outputs and setting a decision threshold, e.g., considering all images with > 50 predicted regions as “complex.” If we vary this threshold and plot a precision-recall curve (preliminary result below), we see that the regression model outperforms the classification model! This makes sense given that the regression model had access to much more data during training.
Our discussions during and after my presentation generated many more ideas about further experiments and analyses I can conduct as I wrap up my project next week:
-
We know that the COCO dataset has considerable imbalances between the complex/noncomplex classes in many object categories. But how much do the trained models exaggerate this imbalance in their predictions on the validation set? One way to measure this bias is to plot the ratio of complex:noncomplex images in the validation set against the ratio of complex:noncomplex predictions on the validation set. (This idea comes from vislang’s previous work on bias in machine learning, some of which is explorable on this page: Genderless.)
-
Frustratingly, the model seems to be focusing on the content of captions (what types of objects are present) more than subtler linguistic clues (like whether objects are described as “many” or the image is described as “cluttered”). One way of forcing the model to pay more attention to adjectives and other descriptors, and less attention to object categories, would be to replace all nouns in the captions with the word “object(s)” during training. Then the model would be less prone to make mistakes such as labeling the image below as “noncomplex,” just because many bathroom images in the COCO dataset happen to be noncomplex. Instead, we would hope that the model focuses on the fact that this image is described as ‘brightly colored,’ and perhaps also the fact that multiple nouns (toilet, sink, shower) are described in the caption:

I would use a library such as Spacy or NLTK, which have POS tagging functionalities, to carry out this masking of the nouns in captions.
- It’s really best practice to just leave in the black-and-white images in the experiments, instead of filtering them out, as I have been, and acknowledge in the write-up that these images’ groundtruth complexity scores are likely inaccurate due to flaws in the distinct regions algorithm. So, I’ll be rerunning my previous experiments with the full (black-and-white images included) dataset.
Around town this week: Over the weekend, I visited the Museum of Natural Science. They have quite an impressive fossil collection.

Citation for COCO image: Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft COCO: Common Objects in Context. Computer Vision – ECCV 2014, 8693, 740–755. https://doi.org/10.1007/978-3-319-10602-1_48
Precision-recall curve and museum photo are my own.