Week 10 (July 18 - July 22, 2022)
It’s hard to believe I’ve come to the end of my DREU! The past 10 weeks have really flown by.
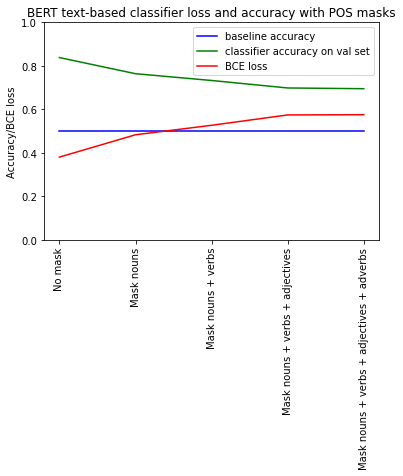
This week I’ve been busy running the vocabulary-masking experiments I discussed in last week’s post. We actually expanded the experiments from our initial idea of masking just nouns, to masking nouns, verbs, adjectives, and adverbs. This means that I trained classification and regression models to predict visual complexity scores from image captions with nouns replaced by the word “object(s),” verbs replaced by the word “act(ing/ed/s),” and adjectives/adverbs replaced by the word “plain(ly/er/est).”
Surprisingly, even after removing much of the descriptive content of captions, the models retain a high degree of accuracy in predicting visual complexity:
To put this in context, a real example of a “masked” caption is “a object in a object object acted with objects.”
I was puzzled by how the classification/regression models could achieve relatively high accuracy with much less detailed text inputs, but it appears there are still some hints as to object categories remaining in the captions, just from POS such as prepositions! For example, images of airplanes flying through the sky and people skiing down slopes in the COCO dataset tend to be relatively noncomplex. The model seems to pick up on this by classifying captions including words like “down” (as in, “skiing down a hill”) as noncomplex:
Example caption: “object in plain and plain acting down the object of a object” [this is a skiing image] Predicted complexity score: 0.099
This just goes to show that it’s incredibly difficult to disentangle information about the types of objects or activities portrayed in an image from its description. We wanted the model to focus more on other aspects of the sentence structure (e.g., presence of singular v. plural nouns, adjectives like “cluttered”) but it has proved hard to do this.
One last test of how many non-content/vocabulary-related complexity cues the model is picking up is to perform cross-domain evaluation. This means (for example) testing a model trained on image captions for food images on image captions for animal images. We hypothesize that the model trained on food images should outperform the model trained on the full data in the cross-domain evaluation, because when trained on only images of a single category, the model cannot leverage content-related cues as much: e.g., it cannot use the fact that food is often complex to decide whether images are complex/noncomplex when it only sees food images during training. Then the model must focus more on other cues: is the food described as “colorful”? Are there people described in the caption? And so on.
The other major task I have to complete as my DREU wraps up is writing a technical report. At first, I felt unsure how to approach this, but my meetings with my mentor this week helped me feel a lot more confident about how to go about writing my paper (lots of helpful tips, like reading good papers and trying to emulate them in structuring and styling your own papers, using Keynote/PowerPoint to generate figures, etc.). We also discussed plans to continue meeting once every 1-2 weeks to continue polishing the paper and perhaps running a few more experiments after the end of DREU, with the goal of submitting to a conference.
I also need to provide a bit more detailed documentation for my GitHub repo so that vislang can make use of my code in the future.
Overall, this REU has been a great experience. I’ve enjoyed learning so much about machine learning, computer vision, and NLP this summer, getting to know some of the members of the vislang lab better, and exploring Houston’s Museum District. I’m thankful to everyone who encouraged me and helped me to apply to this program; my DREU mentor, Professor Ordóñez-Román; and the DREU organizers for making this program possible.
 Where I’ve been working from these past few weeks.
Where I’ve been working from these past few weeks.